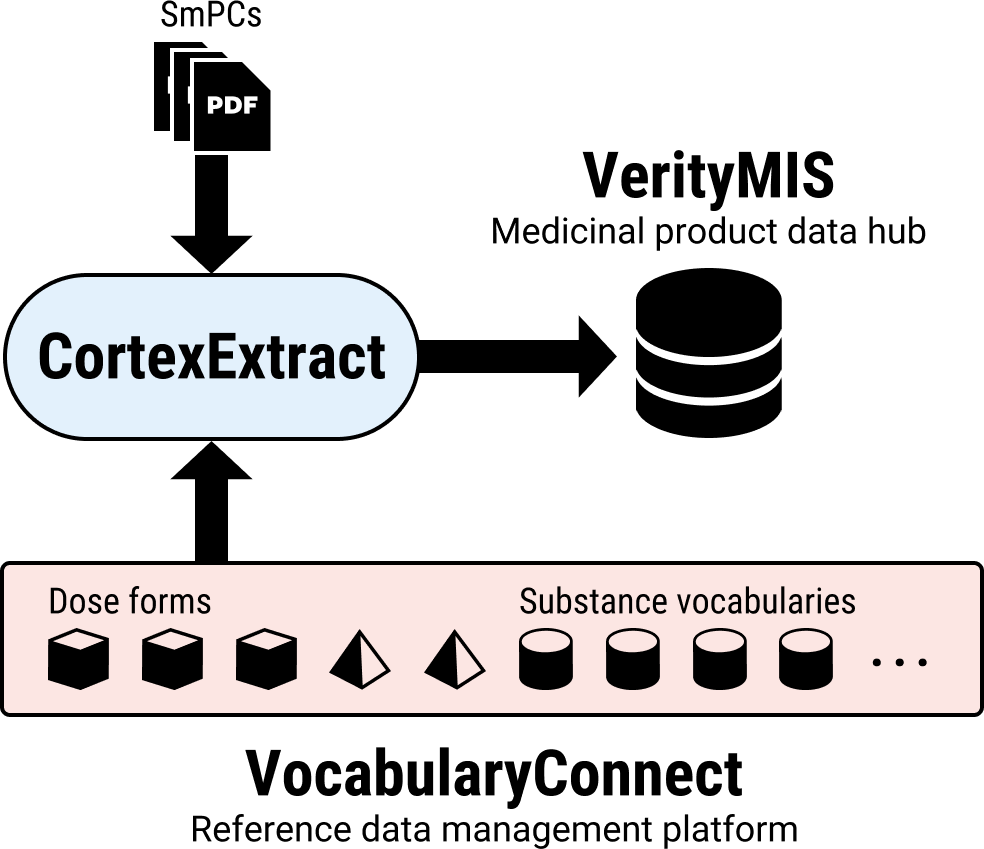
VocabularyConnect
Reference data are crucial for semantic interoperability. Our solution for managing these is OntoPharma’s VocabularyConnect reference data management platform.
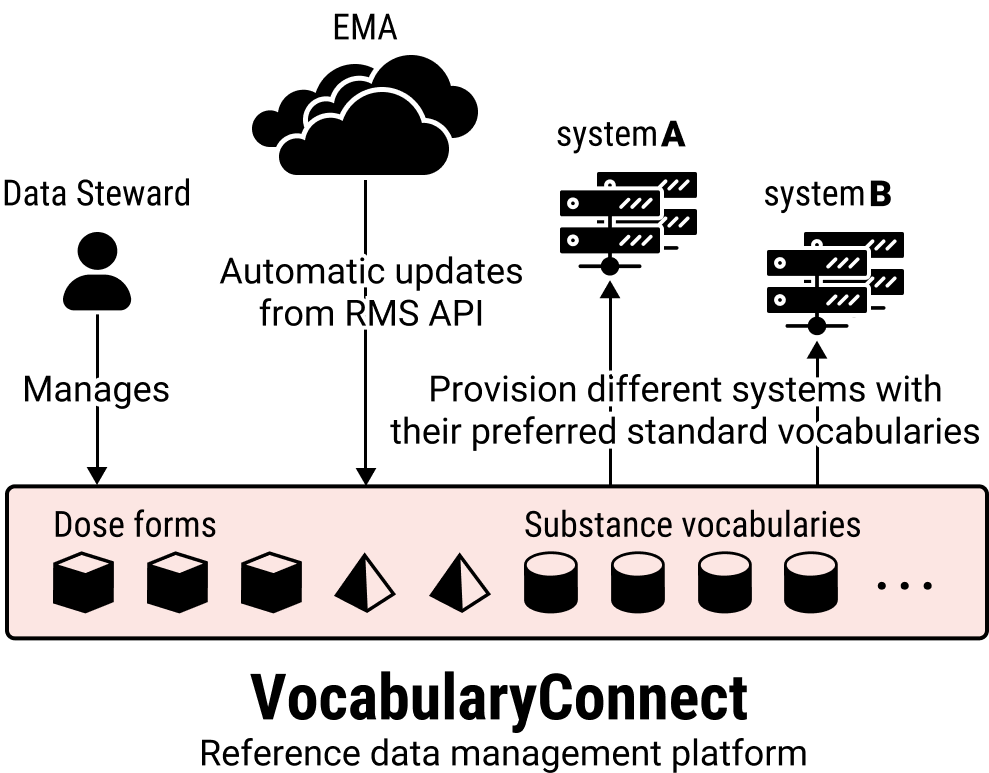
VocabularyConnect is based on state of the art reference data management tooling. It supports the Data Steward in all management tasks. Vocabularies designated by the EMA, such as the ATC vocabulary for substances, are kept up to date automatically through the RMS API. This is done in autogenerated Working Copies that the Data Steward can release to production whenever opportune.
Other vocabularies in the same terminology group, such as DrugBank codes (which may be needed by systems inside or outside your enterprise), also need to be versioned and kept up to date. The same is true of the crosswalks that translate between items in different vocabularies inside the same terminology group. Managing these vocabularies in a disciplined way is the very essence of IDMP readiness and the start for Web-scale semantic interoperability.
Read more in our white paper.